 Intro to Big Data
Intro to Big Data
Week 10 | Lesson 1.1
LEARNING OBJECTIVES
After this lesson, you will be able to:
- recognize big data problems
- explain how the map reduce algorithm works
- perform a map-reduce on a single node using python
STUDENT PRE-WORK
Before this lesson, you should already be able to:
- run python scripts from the unix shell
- recall how the
catandsortunix commands work
INSTRUCTOR PREP
Before this lesson, instructors will need to:
- Read in / Review any dataset(s) & starter/solution code
- Generate a brief slide deck
- Prepare any specific materials
- Provide students with additional resources
ADDITIONAL WEEK 10 PREP
This week requires additional prep in order to successfully run all lessons and labs provided:
- Download and install Virtual Machine.
- Note: This is a big file. Please reserve time to download and troubleshoot installation.
- Sign up for AWS Account & Credits.
- Note: Instructors will need to distribute individual URLs for the signup form. See linked instructions.
LESSON GUIDE
| TIMING | TYPE | TOPIC |
|---|---|---|
| 5 min | Opening | Opening |
| 20 min | Introduction | Intro to Big Data |
| 20 min | Guided-practice | Guided Practice: Word Count on paper |
| 20 min | Demo | MapReduce in python |
| 15 min | Ind-practice | Independent practice |
| 5 min | Conclusion | Conclusion |
Opening (5 min)
Congratulations! You've made it to Week 10! This is the last full week of new content, and you already know a ton! Now it's time to think about some major trends in the field, including common tools and problems that data scientists may encounter. It is also time to take the tools you've learned to a new level by scaling up the size of datasets you can tackle. Today we start talking about Big Data!
Check: what do you think Big Data is?
Answer: more data than your laptop can handle, more than 1 computer working together
Big data is a hot topic nowadays. It refers to techniques and tools that allow to store, process and analyze web-scale (multi-terabyte) datasets.
Check: can you think of any dataset like that?
Answer:
- amazon product catalogue
- google's gmail
- any large company server logs
- photos & images
- etc...
Check: what do you think the challenges are when processing such large amount of data?
Answer:
- processing time
- cost
- architecture maintenance and setup
- hard to visualize
Intro to Big Data (20 min)
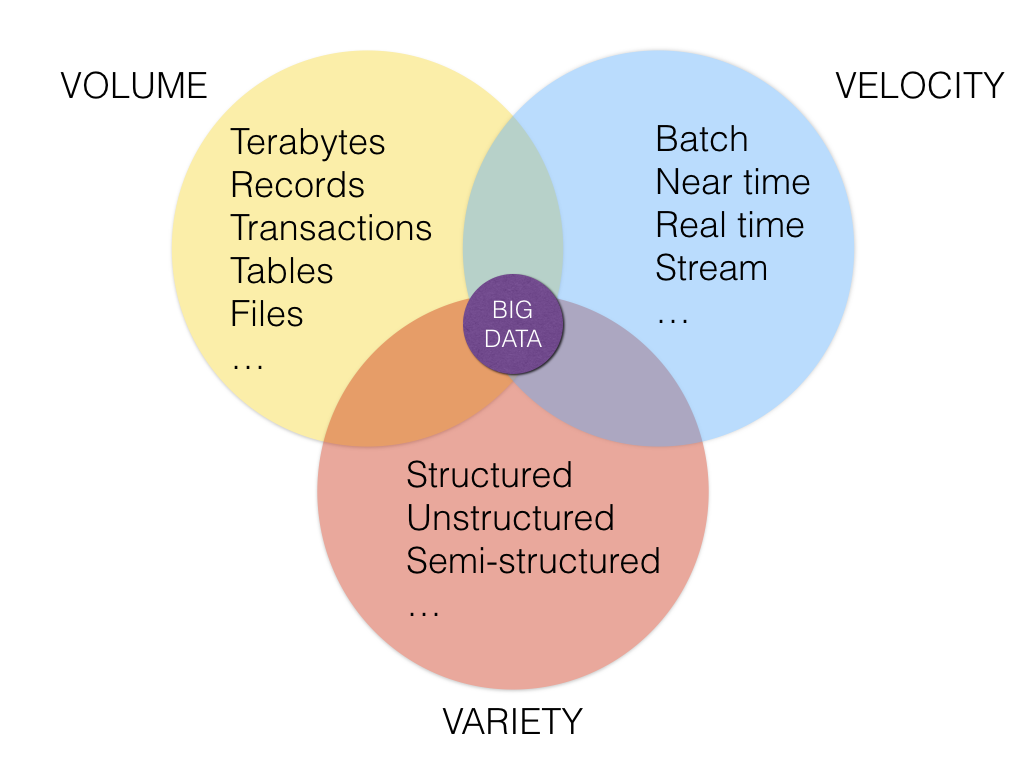
Big data is a term used when the data exceeds the processing capacity of typical database. We need a big data analytics when the data grows quickly and we need to uncover hidden patterns, unknown correlations, and other useful information. There are three main features in big data (the 3 "V"s):
- Volume: Large amounts of data
- Variety: Different types of structured, unstructured, and multi-structured data
- Velocity: Needs to be analyzed quickly
Two approaches to Big Data: HPC and Cloud.
High performance Computing
Supercomputers are very expensive, very powerful calculators used by researchers to solve complicated math problems.

Check: Can you think of advantages and disadvantages of this configuration?
Answer:
pros:
- can perform very complex calculation
- centrally controlled
- useful for research and defense complicated math problems
cons:
- expensive
- difficult to maintain
- scalability is bounded
Cloud computing
Instead of one huge machine, what if we got a bunch of regular (commodity) machines?

Check: Can you think of advantages and disadvantages of this configuration?
Answer:
pros:
- cheaper
- easier to maintain
- scalability is unbounded (just add more nodes to the cluster)
cons:
- only works with problems that are parallelizable
- small cpu power
- more I/O between machines
The term Big Data refers to the latter case, where commodity hardware with unlimited scalability is used to solve highly parallelizable problems.
Divide and Conquer
Divide and conquer strategy is a fundamental algorithmic technique for solving a given task, whose steps include:
- split task into subtasks
- solve these subtasks independently
- recombine the subtask results into a final result
The defining characteristic of a problem that is suitable for the divide and conquer approach is that it can be broken down into independent subtasks.
Map-Reduce
The term Map Reduce indicate a two-phase divide and conquer algorithm initially invented and publicized by Google in 2004. It involves splitting a problem into subtasks and processing these subtasks in parallel and it consists of two phases:
- the mapper phase
- the reducer phase
In the mapper phase, data is split into chunks and the same computation is performed on each chunk, while in the reducer phase, data is aggregated back to produce a final result.
Map-reduce uses a functional programming paradigm. The data processing primitives are mappers and reducers, as we’ve seen.
- mappers – filter & transform data
- reducers – aggregate results
The functional paradigm is good at describing how to solve a problem, but not very good at describing data manipulations (eg, relational joins).
Key Value pairs
Data is passed through the various phases of a map-reduce pipeline as key-value pairs.
Check: what python data structures could be used to implement a key value pair?
Answer:
- dictionary
- tuple of 2 elements
- list of 2 elements
- named tuple
To understand map reduce one needs to always keep in mind that data is flowing through a pipeline as key-value pairs.
Guided Practice: Word Count on paper (20 min)
Let's perform a simple map-reduce in the class, let's find the 10 most common words in the paragraph below.
1: MapReduce is a programming model for large-scale distributed data processing.
3: It is inspired by the map function and the reduce function of the functional
4: programming languages such as Lisp, Haskell, or Python. One of the most
5: important features of MapReduce is that it allows us to hide the low-level
6: implementation such as message passing or synchronization from users and
7: allows to split a problem into many partitions. This is a great way to make
8: trivial parallelization of data processing without any need for
9: communication between the partitions.
10: MapReduce became main stream because of Apache Hadoop, which is an open
11: source framework that was derived from Google's MapReduce paper.
12: MapReduce allows us to process massive amounts of data in a distributed
13: cluster. In fact, there are many implementations of the MapReduce
14: programming model. Some of them are shown in the following list. It is
15: important to say that MapReduce is not an algorithm; it is just a part
16: of a high-performance infrastructure that provides a lightweight
17: way to run a program in a lot of parallel machines.
18: from: Practical Data Analysis, Hector Cuesta, 2013
Simple Map reduce
We will do this as follows:
- Students will perform the mapper function
- Instructor will perform the reducer function
Each student will be assigned 1 line of text, and you have to produce a list of key value pairs (word, 1) and hand those to the instructor.
Check: what pre-processing should you do your tokens in order to improve the results?
Answer: Ignore punctuation and transform all to lower-case
Example: the first line will produce this list:
(MapReduce, 1)
(is, 1)
(a, 1)
(programming, 1)
(model, 1)
(for, 1)
(large-scale, 1)
(distributed, 1)
(data, 1)
(processing, 1)
The instructor will then sort them, add up the 1s for each word and produce the counts.
Instructor notes:
- if there are more than 18 students, group the students to obtain 18 groups
- if there are less than 18 students, give each student more than 1 line, so that all lines get processed
- make sure that they hand a list of key-value pairs where the key is the word and the value is 1
no need to actually do the count, here are the expected results:
('of', 10) ('a', 9) ('is', 8) ('the', 8) ('mapreduce', 7) ('to', 6) ('that', 4) ('it', 4) ('in', 4) ('data', 4)
Check: what additional operation did the instructor perform in order to complete the aggregation?
It had to shuffle the k-v pairs handed by the students in order to find common key and add up the corresponding values.
Combiners
Combiners are intermediate reducers that are performed at node level in a multi node architecture.
When data is really large we will distribute it to several mappers running on different machines. Sending a long list of (word, 1) pairs to the reducer node is not efficient. We can first aggregate at mapper node level and send the result of the aggregation to the reducer. This is possible because aggregations are associative.
Let's repeat the exercise we did before, with a small change.
1.Let's divide the class in 3 groups, in each group one student will be the combiner, the others will be mappers.
- Let's split the text in 3 parts and each group gets one part
- Mapper students produce the same list of
(word, 1)for each line they receive and hand the list to the combiner - Combiner students sort the lists and sum the counts for words that appear in each list
- Finally combiner students hand their list of counts to the instructor who will combine the intermediate sums and produce the final result
Check: What changed?
Less message passing to the instructor
Congratulations! you have just performed a map-reduce sum.
Check: Can you think of other aggregation tasks that can be parallelized in this way?
Answer:
- count, sum, average
- grep, sort, inverted index
- graph traversals, some ML algorithms
MapReduce in python (20 min)
Now that we performed map-reduce in person, let's do it in python. Below you can find the code for a simple mapper and reducer that perform the word count.
Let's look at them in detail.
Mapper.py
# mapper.py
import sys
# get text from standard input
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print '%s\t%s' % (word, 1)
Check: what kind of input does mapper.py expect?
lines of text coming from standard input
Check: what kind of output does mapper.py produce?
key-value pairs separated by a tab, where key is the word and value is 1
Reducer.py
# reducer.py
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
# try to count, if error continue
try:
count = int(count)
except ValueError:
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)
Check: what kind of input does reducer.py expect?
sorted key value pairs
Check: what kind of output does reducer.py produce?
key-value pairs separated by a tab, where key is the word and value is the sum of the counts
The code can be run with the following command from terminal:
cat <input-file> | python mapper.py | sort -k1,1 | python reducer.py
Check: can you explain what each of the 4 steps in the pipe does?
Answer:
- cat: read the file and streams it line by line
- mapper
- sort: shuffles the mapper output to sort it by key so that counting is easier
- reducer: aggregates by word
Check: can you find those in the diagram below?
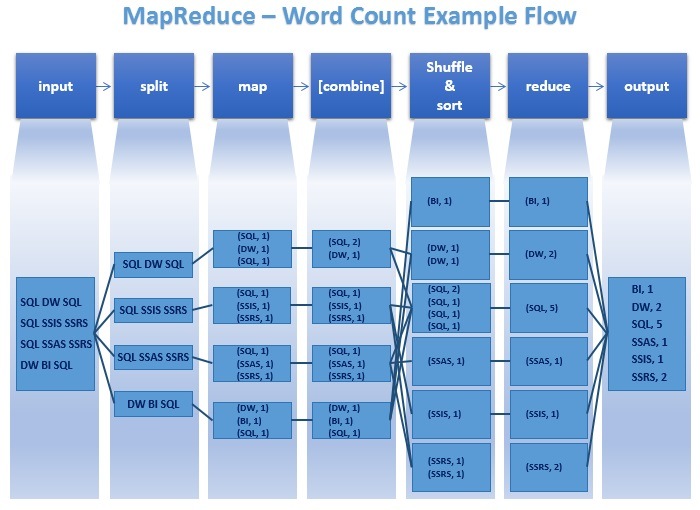
Independent practice (15 min)
Now that you have a basic word count set up in python, try doing some of the following:
- process a much larger text file (you can download it from internet)
for example a page from wikipedia or a blog article. If you're really ambitious you can take books from project gutemberg.
- try to see how the execution time scales with file size
- read this article for some very powerful shell tricks
Conclusion (5 min)
In this class we have learned about Big Data and map-reduce. This is an algorithm that works really well for aggregations on very large datasets.
Check: now that you know how it works can you think of a more specific business application?
Examples:
- process log files to find security breaches
- process medical records to assess spending
- process news articles to decide on investments
Prep for next class:
In preparation for the next class students shoud Download and install Virtual Machine.
- Note: This is a big file. Please reserve time to download and troubleshoot installation.