 Different databases
Different databases
Week 5 | Lesson 1.1
LEARNING OBJECTIVES
After this lesson, you will be able to:
- Recognize common databases and know industry application
- Describe what SQL and noSQL mean
- Describe pros/cons of SQL and noSQL
- Know where the database lives (remote vs local)
STUDENT PRE-WORK
Before this lesson, you should already be able to:
- Students should be familiar with CSV and JSON files
- Students should be familiar with Pandas Dataframes and Python dictionaries
- Students should be able to transfer data to/from Pandas from/to CSV and JSON
INSTRUCTOR PREP
Before this lesson, instructors will need to:
- Read in / Review any dataset(s) & starter/solution code
- Generate a brief slide deck
- Prepare any specific materials
- Provide students with additional resources
- Make sure that the postgreSQL instance is running ok
LESSON GUIDE
| TIMING | TYPE | TOPIC |
|---|---|---|
| 5 min | Opening | Opening |
| 15 mins | Introduction | Intro to Relational Databases |
| 10 mins | Guided | Design a relational database |
| 15 min | Introduction | Alternative databases |
| 10 mins | (Optional) Guided-practice | (Optional) Find the most appropriate storage |
| 10 mins | Demo | Connecting to a Local Database |
| 10 mins | Demo | Connecting to a Remote Database |
| 10 minutes | Ind-practice | Independent Practice |
| 5 mins | Conclusion | Conclusion |
Opening (5 min)
Databases are the standard solution for data storage and are much more robust than text, CSV or JSON files. Most analyses involve pulling data to and from a resource and in most settings, that means using a database.
Databases can come in many flavors, designed for different use cases. We will survey a few applications and explore the most common families of databases: Relational and non-Relational.
Check: What is a Pandas DataFrame?
Check: What is a Python dictionary?
Intro to Relational Databases (15 mins)
- Databases are computer systems that manage the storage and querying of data. * Databases provide a way to organize data along with efficient methods to retrieve specific information.
- Databases also allow users to create rules that ensure proper data management and verification.
Typically, retrieval is performed using a query language the most common of which is SQL (Structured Query Language).
Industry Example 1
Databases are very commonly used at banks. A bank needs to keep track of all the money in each of its clients' accounts. Let's suppose that the bank stores these as numbers in a table with two columns:
| ACCOUNT_ID | BALANCE |
|---|---|
| 1 | 10.000 |
| 2 | 12.546 |
| 3 | 8761 |
| ... | ... |
Check: If this table was stored in a file in a central bank, what would internet banking look like? What problems could arise?
Look for them to notice problems of:
- consistency (what if two nodes try to read/edit the file at the same time?)
- availability (what if a node is not connected to the central bank?)
- partition tolerance (what if only part of the file is available?)
- scale (what if too many nodes request data from the file at the same time?)
As you may know, when multiple processes/users are interacting with the same data, it quickly becomes impractical to store it in a single file on a single machine. That's where databases comes in.
Transactional Integrity
A unit of work performed against a database is called a transaction. This term generally represents any change in database.
Going back to the bank example, consider the case where you want to transfer money from an account to another.
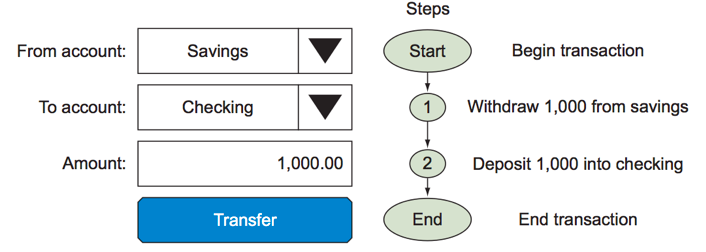
Check: What happens if step 1 succeeds and step 2 fails ?
Check: What if you request the balance between step 1 and step2 ?
The system that stores the data must be resilient to these problems. It must know when a transaction begins, when it ends, what to do if it never ends and what to do if another transaction is requested, while the previous one is still going.
Guaranteeing Transaction Reliability
There is a set of properties known by the acronym ACID that guarantee that database transactions are processed reliably and concurrently:
- Atomicity
- Consistency
- Isolation
- Durability.
Atomicity requires that each transaction be "all or nothing": if one part of the transaction fails, the entire transaction fails, and the database state is left unchanged.
Consistency ensures that any transaction will bring the database from one valid state to another. Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof.
Isolation ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed serially, i.e., one after the other.
Durability ensures that once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors. In a relational database, for instance, once a group of SQL statements execute, the results need to be stored permanently (even if the database crashes immediately thereafter)
This is the typical model under which relational databases operate, and it fits perfectly our previous example of the bank.
Relational Databases
A relational database is a database based tabular data and links between data entities or concepts. Typically, a relational database is organized into tables. Each table should correspond to one entity or concept. Each table is similar to a single CSV file or Pandas dataframe.
For example, let's take a sample application like Twitter. Our two main entities are Users and Tweets. For each of these we would have a table.
A table is made up rows and columns, similar to a Pandas dataframe or Excel spreadsheet. A table also has a schema which is a set of rules for what goes in each table, similar to the header in a CSV file. These specify what columns are contained in the table and what type those columns are (text, integers, floats, etc.).
The addition of type information make this constraint stronger than a CSV file. For this reason, and many others, databases allow for stronger data consistency and often are a better solution for data storage.
Each table typically has a primary key column. This column is a unique value per row and serves as the identifier for the row.
A table can have many foreign keys as well. A foreign key is a column that contains values to link the table to the other tables. For example, the tweets table may have as columns:
- tweet_id, the primary key tweet identifier
- the tweet text
- the user id of the member, a foreign key to the users table
These keys that link the table together define the relational database.
MySQL and PostgreSQL are popular implementations of relational databases. Both of these are open-source, available for free, and are widely-used in industry.
Alternatively, many larger companies may use Oracle or Microsoft SQL databases. While these all offer many of the same features (and use SQL as a query language), the latter also offer some maintenance features that large companies find useful.
Check: Describe in your own words what a relational database is.
Design a relational database (10 mins)
Consider the following dataset from Uber with the follow fields:
- User ID
- User Name
- Driver ID
- Driver Name
- Ride ID
- Ride Time
- Pickup Longitude
- Pickup Latitude
- Pickup Location Entity
- Drop-off Longitude
- Drop-off Latitude
- Drop-off Location Entity
- Miles
- Travel Time
- Fare
- CC Number
Work in pairs and answer the following questions:
- How would you design a relational database to support this data?
- List the tables you would create
- What fields would they contain?
- How would they link to other tables?
Answer: Users table:
- User ID - User Name - Joined Date - CC NumberDrivers table:
- Driver ID - Driver Name - Joined DateLocations table: Should store popular destinations metadata
- Entity - Longitude - Latitude - DescriptionRides:
- Ride ID - Ride Time - User ID (link to users) - Driver ID (link to drivers) - Pickup Location Entity (link to locations) - Drop-off Location Entity (link to locations) - Miles - Travel Time - Fare - CC Number
Alternative databases (15 min)
While relational tables are one of the most popular (and broadly useful) database types, specific applications may require different data organization. While it's not important to know all varieties, it is good to know the overall themes:
Key-value stores
Some databases are nothing more than very-large (and very-fast) hash-maps or dictionaries that can be larger than memory. These are useful for storing key based data, i.e. storing the last access or visit time per user, or counting things per user or customer.
Every entry in these databases is two values, a key and value, and we can retrieve any value based on its key. This is exactly like a python dictionary, but can be much larger than your typically computer memory allows and uses smart caching algorithms to ensure frequently or recently accessed items are quickly accessible.
Popular key-value stores include Cassandra, Redis or memcachedb.
Key-value stores are typically used for: image stores, key-based filesystems, object cache, systems designed to scale.
NoSQL or Document databases
NoSQL databases don't rely on a traditional table setup and are more flexible in their data organization. Typically they do actually have SQL querying abilities, but simply model their data differently.
Many organize the data on an entity level, but often have denormalized and nested data setups. For example, for each user, we may store their metadata, along with a collection of tweets, each of which has its own metadata. This nesting can continue down encapsulating entities. This data layout is similar to that in JSON documents.
Popular databases of this variety include mongodb and couchdb.
Typical uses: high-variability data, document search, integration hubs, web content management, publishing, and many more.
Industry example
Consider the case of large ecommerce website. There is a catalogue with many products. Every product needs to be stored in a database, but different products could have different properties. Also, inventory needs to be tracked, and user carts affect inventory.
Check: What would be the shortcomings of the relational DB model?
Answer:
- schema: different products have different properties, a rigid schema makes it hard to add new products
- scalability
Timeseries databases
Time series databases (TSDB) are optimized for handling time series data, i.e. data that is indexed by time (a datetime or a datetime range).
Examples of time series include stock market data, energy load data from a utility company, server metrics, purchase history, website metrics, ads and clicks, sensor data from a wearable device or an internet-of-things sensor, and smartphone sensor data
Time series pose different challenges that cannot be usually solved with the traditional relational database model.
Check: What issues could arise when modeling time series data with a tabular data model?
answer:
- critical data volume
- time ordering
- out of order inserts
- joins
Popular databases of this variety include: Atlas, Druid, InfluxDB, Splunk
Graph databases
Graph databases are optimized to store data about networks. Most graph databases are NoSQL in nature and store their data in a key-value store or document-oriented database. In general terms, they can be considered to be key-value databases with the addition of the relationship concept.
In traditional relational databases, the relationships are defined within the data itself. In graph databases, relationships allow the values in the store to be related to each other in a free form way. This allows complex hierarchies to be quickly traversed, addressing one of the more common performance problems found in traditional key-value stores.
Most graph databases also add the concept of tags or properties, which are essentially relationships lacking a pointer to another document.
Popular databases of this variety include: Neo4j, OpenCog, AllegroGraph, Oracle Spatial and Graph.
Typical uses: social networks, fraud detection, and relationship-heavy data.
Industry example
Consider a phone company that has information about phone calls. Each phone call entity has the following properties:
- caller_id
- receiver_id
- time_of_call
- duration
Each user makes many calls, and some users may be more connected than others. The company is interested in finding the people that are central in the network of call connections (super connectors), in order to extend them a promotion on their phone usage. The reason for doing this is that they want them to be happy with the company and positively influence the brand image to their connections.
A graph database is perfectly suited to answer such a question.
Other examples could include
- finding communities
- finding shortest path between two entities
- detecting fraudolent behavior
- establishing user identity
BASE (Basically Available, Soft state, Eventual consistency)
An alternative to ACID is BASE and is typically associated with NoSQL databases. The acronym stands for:
- Basically available indicates that the system does guarantee availability.
- Soft state indicates that the state of the system may change over time, even without input.
- Eventual consistency indicates that the system will become consistent over time, given that the system doesn't receive input during that time.
Main concept: get rid of locks, allow everyone to write, worry about consistency later.
Check: How is BASE different from ACID? No guarantee of immediate consistency,
(Optional) Find the most appropriate storage (10 mins)
In pairs or small groups discuss the best storage or database solution for each scenario:
Instructor Note: Many of these the answers may be personal preference, but students should understand some of the differences.
Database for an application with user profiles
- Probably relational DB. It could be a 'noSQL' database if user profile fields are commonly updating or we want to make it easy to do complex queries on user profile elements.
Database for an online store
- Probably a relational DB - Fast storage querying, standard table structures, transactional capabilities
Storing last visit date of a user
- A fast key-value store would be useful for caching interesting statistics about users (last visit, total visits)
Mobile application that allows peer to peer sharing of messages that have short lifetime.
- Probably a graph database for users and a noSQL or key-value store for messages
A hedge fund that needs to record stock market data and run models on them.
- a time series database
Connecting to a Local Database (10 mins)
A database can be local or remote, it can span a single machine or it can be distributed with replicated data over several machines. The latter configuration is called sharding.
Let's start by connecting to a local sqlite database.
SQLite
SQLite is a database software package built on the Structured Query Language (SQL). It is similar to other SQL databases, such as PostgreSQL, MySQL, Oracle, and Microsoft SQL Server, except that it is file-based, rather than server-based. This makes it easy to setup and use for small projects, but less suitable for production environments. Once you are familiar with sqlite, the same ideas, and similar syntax, can be applied to other SQL databases.
SQLite v3 is bundled with most python distributions (including our Anaconda distribution). You might also find it useful to install SQLite Manager, a Firefox add-on for viewing SQLite database files via a simple GUI.
Interacting with SQLite
There are multiple ways of interacting with an SQLite database, including:
- SQLite Command Line Utility
- python
sqlite3package pandasSQL Interface- High-level ORMs (e.g. sqlalchemy, django ORM, etc.)
Let's start with method 1. All of these methods provide some form of wrapper, or set of convenience functions, for interacting with SQLite. Behind the scenes, the Structured Query Language (SQL) itself defines the interface to the database software. This underlying SQL syntax will be visible to a greater or lesser degree depending upon the method that is chosen.
Common SQL Command Patterns
The SQL command set has a rich syntax with numerous options, but most of the commonly used commands follow a few simple patterns. A basic familiarity of these patterns is helpful when working in SQL:
CREATE TABLE ...
ALTER TABLE ... ADD COLUMN ...
INSERT INTO ... VALUES ...
UPDATE ... SET ... WHERE ...
SELECT ... FROM ... WHERE ...
SELECT ... FROM ... JOIN ... ON ...
DELETE FROM ... WHERE ...
1. SQLite Command Line Utility
The first method we'll explore is connecting to SQLite via the built-in command line utility.
Note: the commands in this section should be executed within your normal terminal shell.
To start a new session of the interpreter, simply open your terminal and type sqlite3, followed by the name of the database file. If the file does not yet exist, sqlite will create it.
$ sqlite3 test1.sqlite
SQLite version 3.7.12 2012-04-03 19:43:07
Enter ".help" for instructions
Enter SQL statements terminated with a ";"
sqlite>
Notice that your terminal prompt changes to sqlite>, indicating that you are now entering commands into the sqlite command line utility. Take a quick look at the help command:
sqlite> .help
Display the current databases - you should see the new file test1.sqlite:
sqlite> .databases
Creating tables and adding columns
Create an table called table1 with a single column field1 containing an INTEGER PRIMARY KEY:
sqlite> CREATE TABLE table1 (field1 INTEGER PRIMARY KEY);
Add a few more columns to table1:
sqlite> ALTER TABLE table1 ADD COLUMN field2 VARCHAR(16);
sqlite> ALTER TABLE table1 ADD COLUMN field3 REAL;
sqlite> ALTER TABLE table1 ADD COLUMN field4 TEXT;
Notice the different field types in the ALTER TABLE commands. SQLite supports several different field types, including INTEGERS, variable length VARCHAR character fields (with a max length), TEXT fields, and 'REALS', which are used to store floating point numbers.
Verify that the table was created:
sqlite> .tables
You can check the schema of the table using .schema, which shows the commands that would be needed to create the database tables from scratch.
sqlite> .schema
Notice that in this case, our table1 could have been created with a single command, rather than adding each column separately.
Adding data
Let's add some data:
sqlite> INSERT INTO table1 VALUES (1, 'Henry James', 42, '75 Mission Street, San Francisco, CA');
sqlite> INSERT INTO table1 VALUES (2, 'Carol James', 40, '75 Mission Street, San Francisco, CA');
sqlite> INSERT INTO table1 VALUES (3, 'Jesse James', 12, '75 Mission Street, San Francisco, CA');
Notice that the first column has unique values - this is a requirement for the PRIMARY KEY column. If we try to add a record using an existing PK value we'll get an error:
sqlite> INSERT INTO table1 VALUES (3, 'Julie James', 10, '75 Mission Street, San Francisco, CA');
Error: PRIMARY KEY must be unique
Fortunately, SQLite has some built in functionality to auto-increment the PK value - just set the value of the PK field to NULL when doing the INSERT and it will automatically be set to a valid value.
sqlite> INSERT INTO table1 VALUES (NULL, 'Julie James', 10, '75 Mission Street, San Francisco, CA');
Now that we have some data, take a look at the database using the SQLite Manager Firefox plugin.
- Firefox -> Tools -> SQLite Manager
- Select Connect Database
- Highlight the table and then click the Browse and Search tab
Notice that the value in field1 for the Julie James record has been automatically set to 4.
Updating records
Suppose we need to update an existing record with new data - e.g. maybe Julie James is only 9. For this we use the UPDATE command:
sqlite> UPDATE table1 SET field3=9 WHERE field1=4;
Removing Records
To remove records use the DELETE command:
sqlite> DELETE FROM table1 WHERE field2 like '%Jesse%';
Use SQLite-Manager to verify that the Jesse James record has been removed. To exit the sqlite interpreter type .exit.
sqlite> .exit
Connecting to a Remote Database (10 mins)
Update with AWS configuration settings
Postgresql
Postgresql is a very powerful SQL based relational database.
PostgreSQL syntax
GA provides a PostgreSQL database instance at the following address:
You can connect to it using:
psql -h dsi.c20gkj5cvu3l.us-east-1.rds.amazonaws.com -p 5432 -U dsi_student titanic
password: gastudents
PosgreSQL accepts the same syntax as sqlite, with exception of a few system commands. Here are the most common:
\q: Quit/Exit\c __database__: Connect to a database\d __table__: Show table definition including triggers\dt *.*: List tables from all schemas (if*.*is omitted will only show SEARCH_PATH ones)\l: List databases\dn: List schemas\df: List functions\dv: List views\df+ __function: Show function SQL code.\x: Pretty-format query results instead of the not-so-useful ASCII tables
Suggestions:
- if run with
-Eflag, it will describe the underlaying queries of the\commands (cool for learning!). - Most
\dcommands support additional param of__schema__.name__and accept wildcards like*.*
Comparison
| Task | MySQL | PostgreSQL | SQLite |
|---|---|---|---|
| Connect to a database | mysql <dbname> | psql <dbname> | sqlite3 <filename> |
| Client help | help contents | \? | .help |
| SQL help | help contents | \h | n/a |
| List databases | SHOW DATABASES; | \l | .databases |
| Change database | USE <dbname> | \c <dbname> | n/a |
| List tables | SHOW TABLES; | \dt | .tables |
| Show table | info DESCRIBE <tablename> | \d <tablename> | .schema <tablename> |
| Load data | LOAD DATA INFILE <file> | \i <file> | .import <file> <table> |
| Export data | SELECT ... INTO OUTFILE <file> | \o <file> | .dump <table> |
| Exit the client | quit (or exit) | \q | .exit |
Independent Practice (10 minutes)
Now that you are able to connect to a local or remote database try some of the following:
- create a new table in the database
- add data
- remove data
- alter tables
- list tables
- list schemas
- create a new database
- drop a table
- drop a database
- read the help
Conclusion (5 mins)
Relational databases are the most common. They organize data into tables. Other database types exist, including graph, hash, documents and time-series specific databases. The simplest local database is sqlite and we learnt how to add and remove data from it. We also learnt how to connect to a remote postgreSQL database and few basic SQL commands.